
PubTech Radar Scan: Issue 10
New products & services
Wiley’s Research Exchange, a service that sits in front of their journal submission systems and automatically extracts a manuscript’s metadata so that the author doesn’t have to type anything in, has to be one of the more useful developments of the year. [Video]
Semantic Scholar is introducing TLDRs, or single-sentence automatically-generated paper summaries into their search results, to help researchers decide which summaries are most relevant to their work [Research paper]
SciencePOD are also launching a new AI Summaries solution for research papers. They pitch the benefits as driving usage, enhancing the discoverability of original research, better communication of research findings to wider audiences, reaching new audiences and saving editorial time
Scholarcy upping the summarisation ante by automatically generating posters from manuscripts/prepints
cOAlition S has released the Journal Checker Tool, a search engine that checks Plan S compliance
From July 2021 eLife will only review manuscripts already published as preprints, and will focus its editorial process on producing public reviews to be posted alongside the preprints.
Alex Holcombe and co have developed tenzing, a web-based app that makes it easier for researchers to indicate who did what in their manuscripts using CRediT. Users enter their data into a Google Sheet template and tenzing generates various outputs suitable for the Author Information section of a journal article. [More on Medium]


Infrastructure
A.J. Boston is thinking politically about scholarly infrastructure and how to pay for it. I wonder how much the major commercial publishers currently contribute to community infrastructure like Crossref, ORCID, standards bodies, etc.? Nowhere near 2.5% of annual profits but also not an insignificant amount I suspect. Some publishers do give grants for infrastructure development such as SAGE’s Concept Grant program but these are on a very small scale. There are no easy answers here. No one can wave a magic wand and take the large for-profit publishing companies out of the equation and it seems likely that PlanS will drive even more consolidation within the industry as independent society publishers partner with commercial publishers to guarantee income. Perhaps shareholder activism has some merits? Might take a bit more than the pooled resources of cOAlition-S to make an impact though!
On a similar theme Vanessa Proudman from SPARC Europe highlighted concerns about the financial health of diamond journals/platforms.
Reading the latest hoo-ha over a hypothetical plan to combat digital piracy via the deployment of surveillance software, see also Gabriel J. Gardner’s post, made me wonder to what extent it is possible for [US] librarians to protect patron identities? Proxy servers allowed librarians to provide islands of privacy for readers of subscription content but in an increasingly open and interconnected ecosystem the proxy server approach doesn’t really work because your average researcher is interacting with multiple publisher owned systems that share data and there is no intermediary service to protect privacy. This talk from Hindawi about multi-channel marketing techniques nicely sums up how this works.

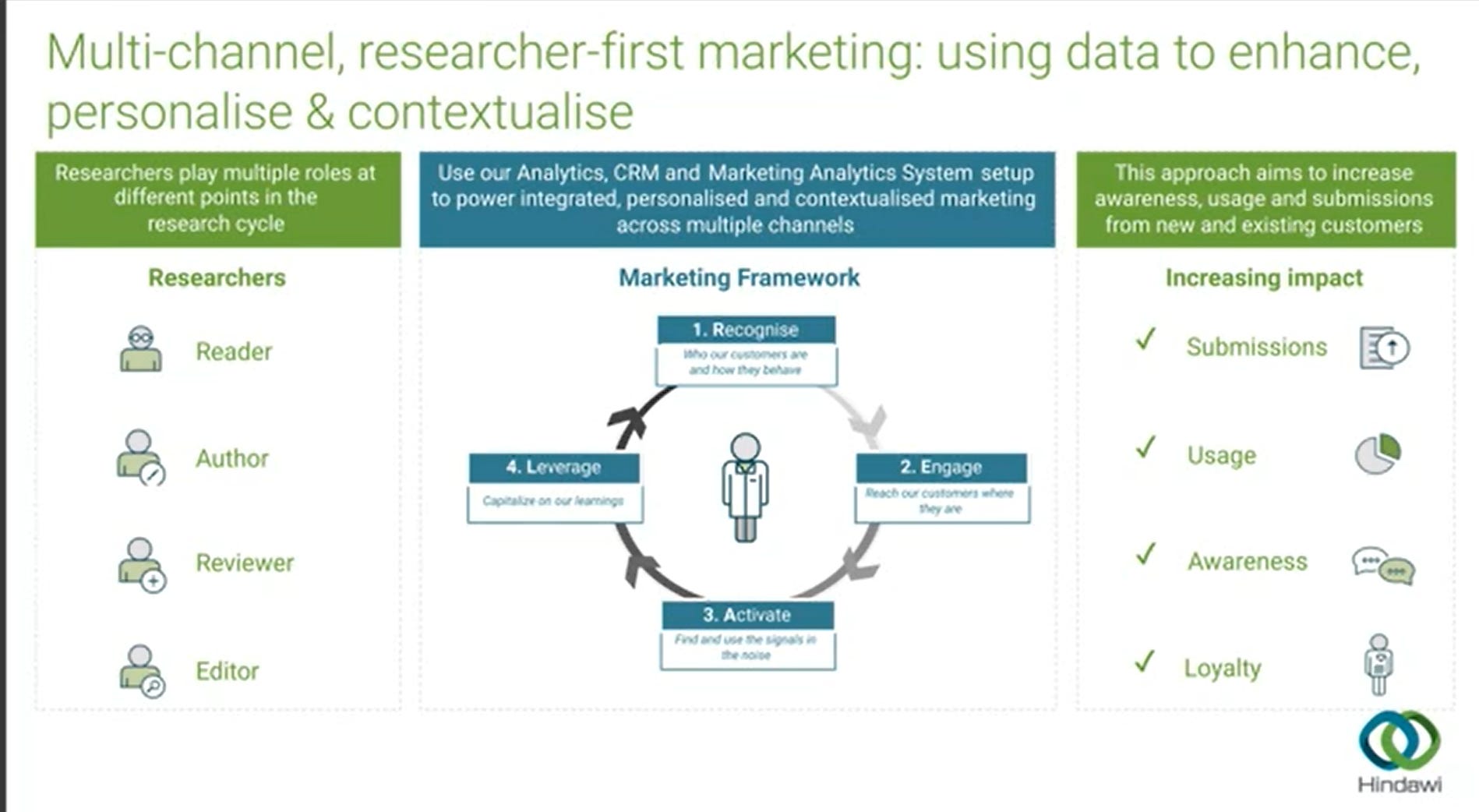
Michael Upshall has a new blog post about recommendation services which includes the question “Do we half-expect that recommended journal articles are the result of a paid placing by the publisher?” Many publishers do pay to promote articles via google and social media and some companies specialise in offering services in this area. Are researchers aware? Probably not. Does it matter? Not sure…